The growth of Large Language Models (LLMs) and multilingual NLP systems has significantly improved language technologies across major global languages. However, low-resource languages such as Sri Lankan Tamil still face a severe lack of high-quality annotated datasets—especially for foundational tasks like Named Entity Recognition (NER).
To address this gap, we developed the Srilankan-Tamil-NER Dataset, a Tamil NER dataset designed specifically for Sri Lankan Tamil linguistic and contextual usage.
This dataset is intended to support:
Why Sri Lankan Tamil NER Matters
Named Entity Recognition (NER) is a core NLP task that identifies and classifies entities such as:
- Person names
- Locations
- Organizations
- Dates
- Miscellaneous entities
NER acts as a foundational layer for many downstream NLP systems including:
- Question answering
- Search systems
- Chatbots
- Document intelligence
- Machine translation
- Knowledge graph generation
For Tamil — particularly Sri Lankan Tamil — publicly available annotated corpora remain extremely limited. Existing multilingual datasets often underrepresent regional linguistic variations, local named entities, and culturally contextual terminology.
Most existing NER systems for Tamil are trained on datasets originating from Indian Tamil corpora, leaving significant gaps in handling:
- Sri Lankan Tamil vocabulary
- Local organization names
- Sri Lankan place names
- Government and institutional terminology
Our dataset aims to bridge this gap.
About the Dataset
The primary goal of this dataset is to create a high-quality manually curated Named Entity Recognition corpus for Sri Lankan Tamil.
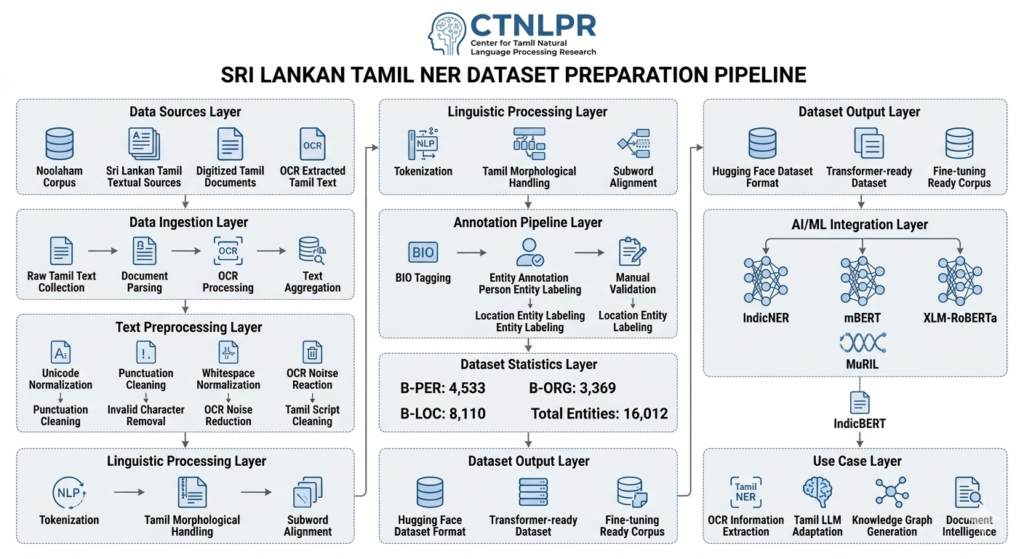
The dataset is structured to support fine-tuning transformer-based multilingual models such as:
- IndicNER
- mBERT
- XLM-RoBERTa
- MuRIL
- IndicBERT
IndicNER itself was trained for multiple Indian languages including Tamil and has become a strong baseline for multilingual NER systems.
Dataset Preparation Pipeline
Creating a Tamil NER dataset involves significantly more than simple annotation.
The preparation workflow included multiple stages:
1. Data Collection
The raw Tamil text corpus was collected from the Noolaham corpus and other relevant publicly available Sri Lankan Tamil textual sources. Special attention was given to:
- local linguistic relevance
- entity diversity
- sentence quality
- contextual richness
The objective was to capture realistic Sri Lankan Tamil usage patterns rather than synthetic or translated text.
2. OCR and Text Normalization
Tamil NLP pipelines often begin with scanned or image-based documents.
As part of our broader Tamil document intelligence workflow, OCR-extracted Tamil text underwent:
- Unicode normalization
- punctuation cleaning
- whitespace normalization
- invalid character filtering
- OCR noise reduction
OCR-related preprocessing becomes extremely important because Tamil script errors can propagate heavily into token classification systems.
3. Named Entity Annotation
The dataset was manually annotated using BIO tagging format:
| Tag Type | Description |
|---|---|
| B-PER | Beginning of person entity |
| I-PER | Inside person entity |
| B-LOC | Beginning of location entity |
| I-LOC | Inside location entity |
| B-ORG | Beginning of organization entity |
| I-ORG | Inside organization entity |
| O | Non-entity token |
BIO tagging remains one of the most widely adopted standards for NER annotation pipelines.
Example:
| Token | Label |
|---|---|
| இராமநாதன் | B-PER |
| யாழ்ப்பாணம் | B-LOC |
| பல்கலைக்கழகம் | B-ORG |
Challenges in Sri Lankan Tamil NER
Building a Tamil NER dataset introduced several language-specific challenges.
Morphological Complexity
Tamil is morphologically rich, where suffixes and grammatical inflections can alter token boundaries significantly.
This creates difficulties for:
- tokenizer alignment
- entity span detection
- subword classification
OCR Noise
Tamil OCR systems still produce:
- broken grapheme clusters
- merged tokens
- Unicode inconsistencies
- punctuation corruption
NER systems trained on clean datasets often fail under noisy OCR conditions.
Limited Existing Corpora
Compared to English, Tamil lacks:
- large benchmark corpora
- standardized annotation frameworks
- domain-diverse datasets
- region-specific entity resources
Several studies have highlighted the low-resource limitations of Tamil and Sinhala NER ecosystems.
Dataset Design Considerations
During preparation, the following design principles were prioritized.
Entity Diversity
The corpus includes diverse entity categories relevant to Sri Lankan contexts.
Examples include:
- government institutions
- educational organizations
- local geographic locations
- personal names
- cultural entities
Fine-Tuning Use Cases
This dataset can be used to fine-tune transformer architectures for:
| Use Case | Description |
|---|---|
| Tamil NER | Entity extraction |
| OCR Post-processing | Structured information extraction |
| Search Systems | Semantic indexing |
| RAG Pipelines | Entity-aware retrieval |
| Tamil Chatbots | Context understanding |
| Government Document AI | Information extraction |
| Knowledge Graphs | Entity linking |
Importance for Low-Resource NLP
The broader importance of this dataset extends beyond NER itself.
Low-resource language ecosystems require foundational datasets before advanced systems such as LLMs, multilingual agents, and reasoning pipelines can perform effectively.
Datasets like this contribute toward:
- Sri Lankan Tamil digital preservation
- multilingual AI inclusivity
- regional NLP research
- culturally aware AI systems
Recent multilingual NER research also highlights the importance of publicly available Tamil and Sinhala annotated corpora for improving low-resource NLP systems.
Future Directions
Planned future improvements include:
- expanding entity categories
- larger corpus coverage
- nested entity support
- OCR-noisy benchmark subsets
- cross-domain annotations
- multilingual Tamil-Sinhala-English alignment
- relation extraction extensions
Conclusion
The Srilankan-Tamil-NER Dataset, developed under CTNLPR, represents an important step toward strengthening the Sri Lankan Tamil NLP ecosystem through high-quality entity annotation and linguistically relevant corpus preparation.
By focusing on realistic Sri Lankan Tamil usage, OCR-aware preprocessing, and transformer-ready annotation formats, the dataset aims to support future advancements in:
- Tamil NLP
- multilingual transformers
- document intelligence
- AI for low-resource languages
As multilingual AI systems continue evolving rapidly, foundational datasets such as this remain critical for improving language inclusivity and advancing Tamil-focused NLP research.
#SriLankanTamil #TamilNER #TamilNLP #NamedEntityRecognition #LowResourceNLP #IndicNLP #BIOtagging #LLM #RAG #SemanticSearch #KnowledgeGraphs #CTNLPR #EntityExtraction