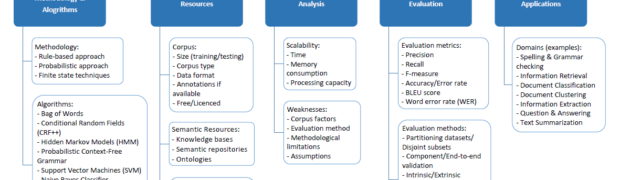
Summary: This project conducts a comprehensive gap analysis of existing digitization, natural language processing, and knowledge engineering capabilities for Sri Lankan Tamil, followed by the development of targeted NLP tools to address identified limitations. It delivers an end-to-end AI system that ingests, processes, and enriches digitized texts and documents to produce structured, reliable, and trustworthy ...